
Why do you need Apache Iceberg?
Why Modern Data Lakes Need Apache Iceberg: Understanding Its Purpose

Storing data in a data lake as individual files might seem like a straightforward solution at first. After all, modern data formats like Apache Parquet provide efficient storage and faster analytics. However, as your data grows and your analytics needs become more complex, you'll quickly discover that a simple file-based approach isn't enough.
In this post, we'll explore why organizations need a sophisticated table format like Apache Iceberg to manage their data lakes effectively. We'll examine how storing large amounts of data in a data lake presents challenges as the data volume grows, and see how Iceberg's modern architecture solves these pain points.
Problem Context
Does storing Parquet files in an object storage solve all your data problems?
Imagine running a large e-commerce platform that processes millions of transactions daily. These transactions are stored in operational databases before moving to a data lake through ETL pipelines. Your data team queries the data lake to understand customer behavior, monitor inventory changes, and generate sales reports. However, as the business grows, you start to identify several critical challenges.

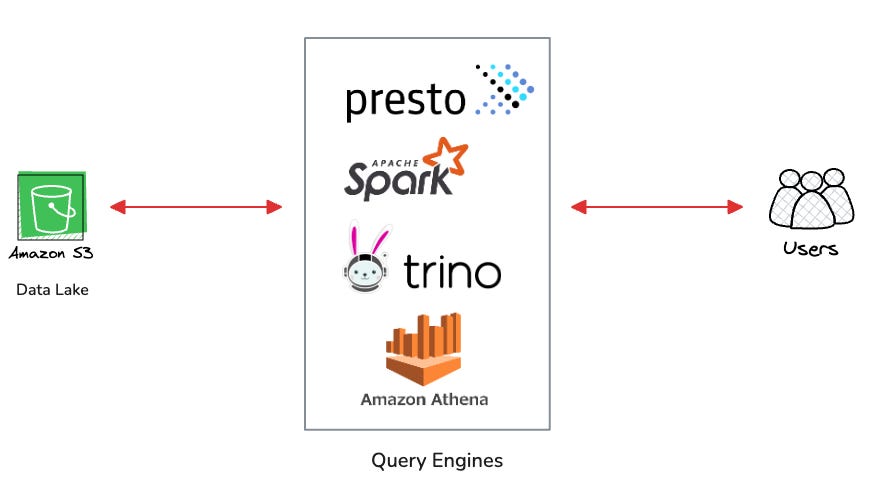
To query this data lake structure efficiently, we leverage specialized technologies designed for big data processing. SQL engines like Apache Spark, Presto, or Trino can directly query the data files using their native SQL interfaces. These engines are particularly effective when working with columnar file formats like Apache Parquet or ORC, which store data in a column-oriented manner for better compression and faster analytical queries.
For example, using Spark SQL, you could query the sales data with a simple command:
spark.sql("""
SELECT * FROM parquet.`data_lake/sales/year=2024/month=03/*/*.parquet`
WHERE amount > 1000
""")Let's look at how this data is typically organized in a traditional data lake structure:
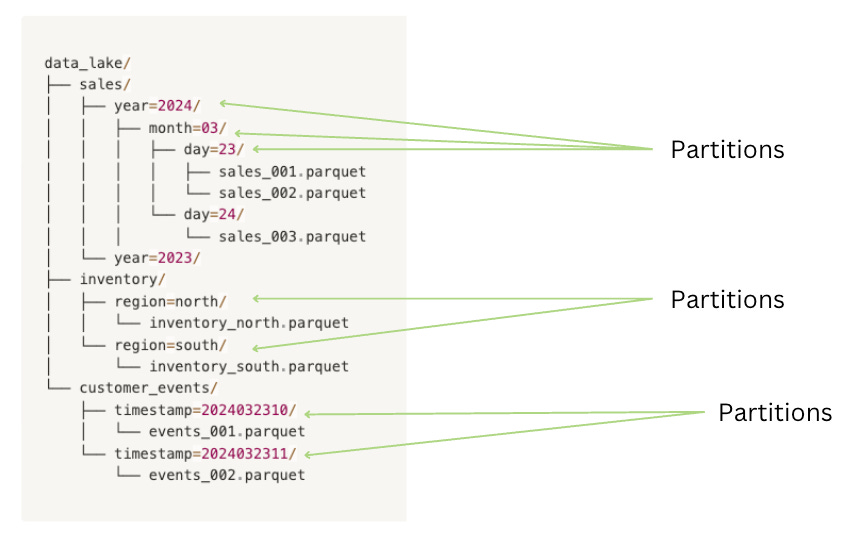
Pain Point 1: The "Directory Listing" Problem
Your analysts run a query to analyze last month's sales data. The query takes forever to execute because your system needs to scan through thousands of files to find the relevant data. This is known as the "directory listing" problem, where systems must perform expensive metadata operations just to start reading data.
Here's an example SQL query to analyze last month's sales data:
SELECT
date_trunc('day', sale_date) as sale_day,
COUNT(*) as total_transactions,
SUM(amount) as daily_revenue,
AVG(amount) as avg_transaction_value
FROM sales
WHERE sale_date >= date_trunc('month', current_date - interval '1 month')
AND sale_date < date_trunc('month', current_date)
GROUP BY date_trunc('day', sale_date)
ORDER BY sale_day;
This query would face the directory listing problem mentioned, as the system would need to scan through numerous files to gather the last month's data.
Pain Point 2: Consistency Challenges
During peak sales periods, multiple teams are simultaneously writing data to your lake. Some processes are updating inventory counts while others are recording new sales. Without proper table management, you might end up with inconsistent data, phantom reads, lost updates, or even corrupted files.
Here's a practical example to illustrate the consistency challenges:
-- Process 1: Updating inventory (Time: 2:00:00 PM)
UPDATE inventory
SET quantity = quantity - 5
WHERE product_id = 'ABC123';
-- Process 2: Reading inventory (Time: 2:00:01 PM)
SELECT quantity
FROM inventory
WHERE product_id = 'ABC123';
-- Process 3: Another update (Time: 2:00:02 PM)
UPDATE inventory
SET quantity = quantity - 3
WHERE product_id = 'ABC123';
Without proper transaction management:
Process 1 starts updating the quantity
Process 2 might read the data before Process 1 completes (phantom read)
Process 3 might base its update on stale data, potentially losing Process 1's changes (lost update)
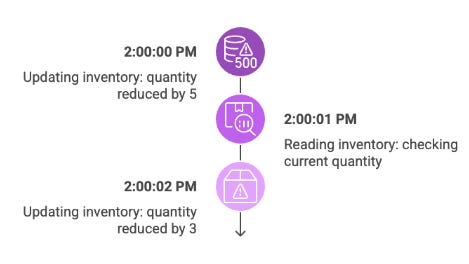
This scenario can lead to incorrect inventory counts and data inconsistencies, which could result in overselling products or making incorrect business decisions based on inaccurate data.
Pain Point 3: Schema Evolution Headaches
Your team needs to add new columns to track additional customer attributes. In traditional data lakes, this seemingly simple change becomes a nightmare, requiring coordination across all consuming applications and potentially breaking existing queries.
This challenge occurs because traditional data lakes store data in files with fixed schemas. When you add or remove columns, you essentially create a mismatch between the old and new data formats. Each consuming application expects data in a specific structure, and when that structure changes, the applications need to be updated to handle both the old and new formats. Moreover, to maintain consistency across your dataset, you often need to rewrite all existing data files to include the new columns or remove deleted ones - a process that can take hours or even days for large datasets. This mass rewriting of data is not only time-consuming but also resource-intensive and risky, as any interruption during the process could leave your data lake in an inconsistent state.
Here's an example of schema evolution in a traditional data lake:
-- Original table structure
CREATE TABLE customers (
customer_id STRING,
name STRING,
email STRING
);
-- Need to add new columns
ALTER TABLE customers
ADD COLUMN phone_number STRING,
ADD COLUMN preferred_contact_method STRING;
-- This change could break existing queries like:
SELECT customer_id, name, email
FROM customers
WHERE email LIKE '%@example.com';
-- Applications expecting only the original columns might fail
-- Data processing jobs might need to be updated
-- Historical data might have missing values for new columns
This demonstrates how a simple schema change can impact multiple systems and require significant coordination across teams.
Pain Point 4: Performance Issues at Scale
As your dataset grows into petabytes, queries become increasingly slower. Without proper partitioning and file optimization strategies, even simple analyses become resource-intensive operations.
Consider a scenario where your analytics team needs to run a query to calculate the average order value per customer segment over the past year. Without proper optimizations, this query would need to:
Scan through millions of files across multiple directories
Read and process data that might not be relevant to the query
Deal with suboptimal file sizes (either too many small files or few very large files)
For example, a simple query like this could take hours to complete:
SELECT
customer_segment,
COUNT(DISTINCT customer_id) as customer_count,
AVG(order_total) as avg_order_value
FROM sales
WHERE order_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 1 YEAR)
GROUP BY customer_segment;
The performance degradation becomes especially noticeable during peak business hours when multiple teams are running concurrent analyses on the same dataset.
Now that we understand the challenges, let’s see how Iceberg can solve them.
Enter Apache Iceberg: The Modern Table Format Solution
Apache Iceberg is a table format specifically designed to solve these challenges in data lake environments. Let's see how it addresses each pain point.
Solution 1: Fast Queries with Intelligent Metadata Management
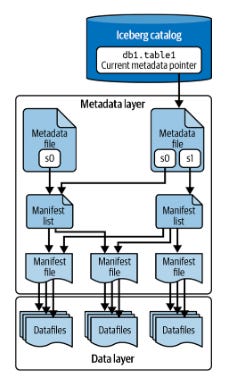
Iceberg maintains a snapshot-based metadata layer that tracks all files in a table. Instead of listing directories, queries can quickly identify relevant files using metadata, dramatically improving query planning and execution times.
When processing a read query, Iceberg's metadata layer acts as an intelligent index, providing a fast path to the exact files needed. The metadata contains detailed statistics about each data file, including value ranges, null counts, and file locations. When a query is executed, Iceberg first consults this metadata to determine which files contain relevant data, eliminating the need to scan entire directories. This manifest-based approach means that instead of listing thousands of files in a filesystem, Iceberg can quickly filter out irrelevant files based on their statistics, significantly reducing I/O operations and improving query performance
Solution 2: ACID Transactions for Data Consistency
Iceberg provides atomic operations and isolation through its snapshot model. Each write operation creates a new table snapshot, ensuring consistency even with concurrent readers and writers.
Iceberg's snapshot isolation works by maintaining a version history of table states. Each snapshot represents a point-in-time view of the entire table, including its metadata and data files. When a writer starts a new transaction, it works with the current snapshot but doesn't modify it directly. Instead, it creates a new snapshot that becomes visible only when the transaction commits successfully. Meanwhile, concurrent readers continue to see a consistent view of the data from their starting snapshot, eliminating the risk of dirty reads or inconsistent analysis. This approach ensures that readers never see partial or uncommitted changes, while allowing multiple writers to work simultaneously without blocking each other.
-- Multiple operations in a single atomic transaction
BEGIN TRANSACTION;
INSERT INTO sales VALUES (...);
UPDATE inventory SET quantity = quantity - 1;
COMMIT;

Solution 3: Schema Evolution Made Simple
With Iceberg, schema evolution becomes straightforward. You can add, drop, or modify columns without affecting existing queries. The format maintains schema history and ensures backward compatibility.
-- Add new columns without breaking existing queries
ALTER TABLE customers
ADD COLUMN loyalty_tier STRING,
ADD COLUMN last_purchase_date TIMESTAMP;
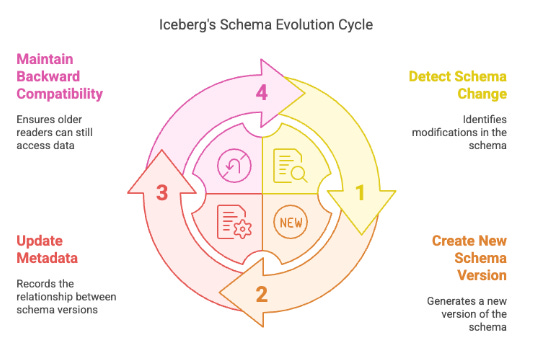
Iceberg's schema evolution works by maintaining a schema history within its metadata. When a schema change occurs, Iceberg creates a new schema version without modifying existing data files. Instead, it updates the metadata to track the relationship between old and new schemas.
Key features of Iceberg's schema evolution include:
Column addition and removal without data rewrites
Type promotion (e.g., int to long) with backward compatibility
Field reordering without impacting existing data
Optional fields for backward compatibility with older readers
This approach means that existing queries continue to work with their expected schema version, while new queries can take advantage of the updated schema. The schema changes are atomic and transactional, ensuring consistency across all operations.
Solution 4: Optimized Performance with Smart Partitioning
Iceberg introduces hidden partitioning and partition evolution, allowing tables to be optimized for different query patterns without rewriting data. It also supports file-level statistics and partition pruning for faster queries.
Iceberg's hidden partitioning is a powerful feature that abstracts the complexity of partition management from users while maintaining performance benefits. Unlike traditional partitioning schemes, where partition columns are explicitly defined in the table schema, Iceberg handles partitioning internally through partition specs.
Key aspects of hidden partitioning include:
Partition fields are stored in metadata, not in the data itself
Multiple partition specs can exist for different snapshots of the same table
Supports complex partition transforms like truncate, bucket, and time functions
Partition evolution in Iceberg allows you to change how a table is partitioned without expensive data rewrites. For example, you might start with daily partitions, but as your data grows, you could switch to monthly partitions for older data while maintaining daily partitions for recent data.
-- Example of partition evolution
ALTER TABLE sales
SET PARTITION SPEC (
month(order_date), -- Switch from daily to monthly partitioning
bucket(16, customer_id) -- Add customer_id bucketing
);
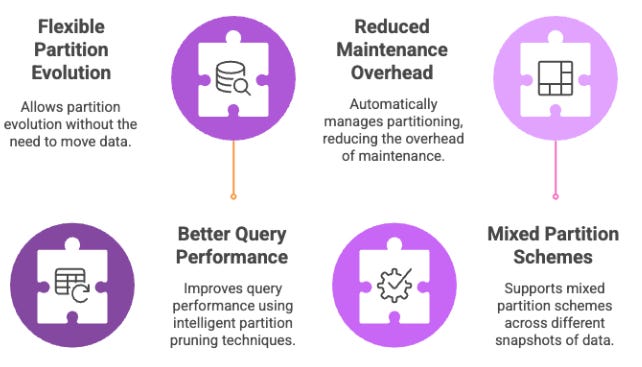
Benefits of Iceberg's partitioning approach:
Flexible partition evolution without data movement
Better query performance through intelligent partition pruning
Reduced maintenance overhead as partitioning is managed automatically
Support for mixed partition schemes across different snapshots
Wrapping it up
In this post, we discussed the limitations of storing data as individual files in a data lake, even with efficient formats like Apache Parquet. As data volumes increase and analytics needs evolve, organizations face several challenges, such as:
1. Directory Listing Problem: Inefficiencies arise when querying large datasets, requiring extensive file scanning.
2. Consistency Challenges: Concurrent processes can lead to data inconsistencies and errors, like phantom reads and lost updates.
3. Schema Evolution Headaches: Fixed schemas can create complications when modifying data structures, necessitating resource-intensive rewrites.
4. Performance Issues at Scale: Large datasets can result in slow query performance, especially during peak times, without proper optimization.
To address these challenges, we introduced Apache Iceberg, a modern table format that provides features like intelligent metadata management, enabling faster queries, improved consistency through transaction management, and efficient handling of schema changes. Iceberg's architecture helps manage data lakes more effectively as they scale, ensuring better performance and reliability.