
Apache Arrow - The Missing Deep Dive Series - Part 1
Let's learn Apache Arrow by first understanding what it can do, then exploring how it works.

Apache Arrow is a software development framework that standardizes how data is stored and shared between different systems. Think of it as a common language that lets different programs work with data efficiently.
A critical component of Apache Arrow is its in-memory columnar format, a standardized, language-agnostic specification for representing structured, table-like datasets in-memory. This data format has a rich data type system (including nested and user-defined data types) designed to support the needs of analytic database systems, data frame libraries, and more.
That's quite a bit of technical jargon! To better understand Apache Arrow, let's focus first on what it can do rather than what it is. This approach helps avoid getting overwhelmed by Arrow's vast complexity and related concepts.
Let's take a first-principles approach: we'll explore how Arrow works in real-world scenarios, explore its capabilities, and then dive into its implementation details—moving from the trunk to the branches and leaves, so to speak.
I'll guide you through three common data sharing scenarios. We'll first look at the challenges that arise without Arrow, then see how Arrow elegantly solves these problems while showcasing its key features.
Sounds good? Let’s dive in.
Assume we have the following tabular data set, which will be shared across different scenarios in the coming sections. Let’s call it the customer data set.
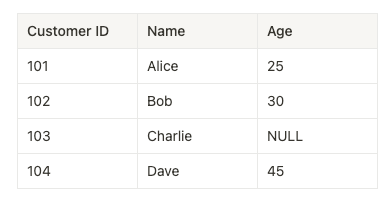
Scenario 1: Sharing a Tabular Dataset Across Different Libraries in the Same Process
Imagine sharing this dataset between Pandas and NumPy within a Python program. We can see several challenges coming in.
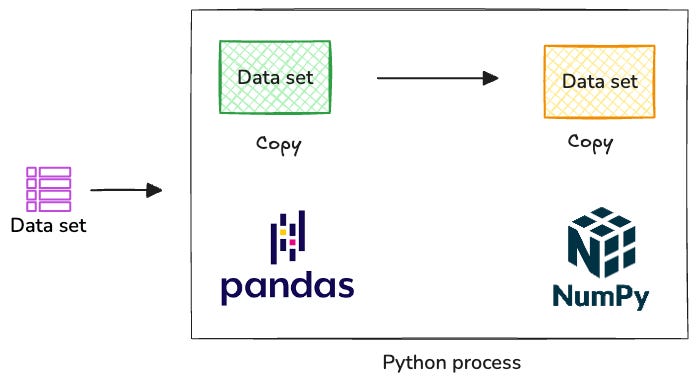
The primary issue is that the dataset must be serialized and deserialized between libraries. Since each library has its own memory representation—including data types and memory layout—they must convert the dataset into a common format. This conversion process creates performance bottlenecks, wasting CPU cycles and introducing delays.
The format conversion also forces each library to maintain full copies of the same dataset, which doubles or triples memory usage. As datasets grow larger, this can lead to memory exhaustion. Additionally, these conversions may introduce subtle data type incompatibilities, as libraries can interpret data types differently (e.g., datetime formats, string encodings, handling of missing values).
Scenario 2: Sharing a Tabular Dataset Across Two Processes Within the Same Machine
Let’s say we have a Java program (producer) and a Python program (consumer) running on the same machine. Java producers want to share this data set with the Python consumer.
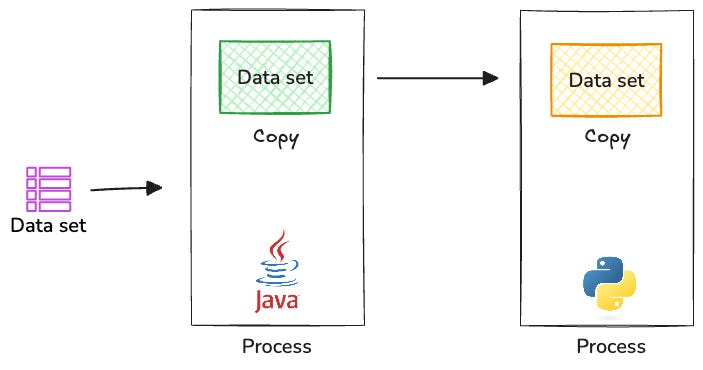
Again, serialization/deserialization is mandatory here. The Java producer must serialize the data into a format suitable for inter-process communication (IPC) and the Python consumer must deserialize it. This conversion requires both programs copying the same data set as before, leading to performance bottlenecks and memory inefficiencies. The serialization format may also have limited support for rich data structures, potentially failing to preserve the original data's complete structure and metadata.
Most importantly, both programs must choose and implement an IPC mechanism (e.g., pipes, sockets, shared memory with custom management). These can be complex to set up and manage correctly (especially shared memory).
Scenario 3: Sharing a Tabular Dataset Across Two Processes Across the Network:
In this case, assume the same Java producer sends the data set to a Python producer across the network.
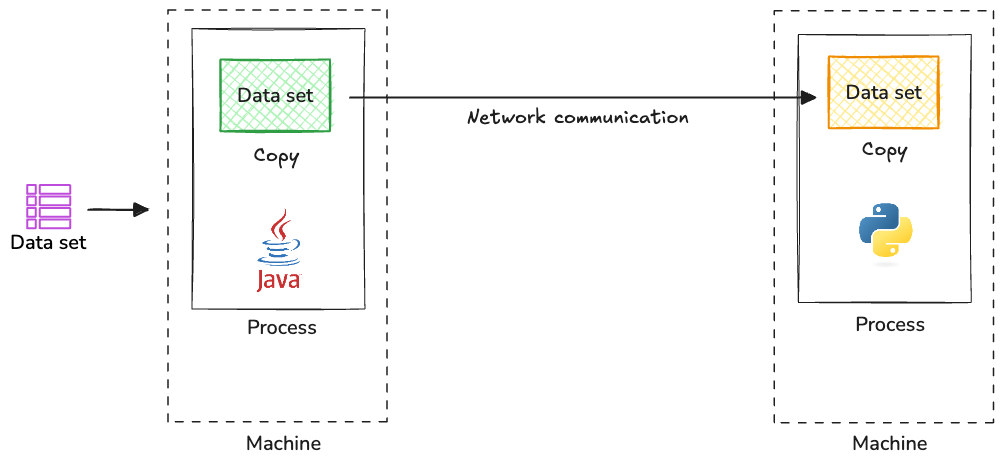
You will run into the same set of problems again. The data set must be serialized into a network-friendly format (e.g., JSON, Protocol Buffers, MessagePack), which results in keeping multiple copies of the same data set as well as data type inconsistencies.
Schema management is another key challenge. Text formats like JSON and binary formats like Protocol Buffers each have their trade-offs. JSON is easier to work with but takes up more network bandwidth, while Protocol Buffers is more compact but less portable across different architectures. Without proper schema management, the sender and receiver can get out of sync about the data structure.
There's also no way to grab just the data columns you need—you have to transfer the whole dataset every time.
Overarching pain points, Arrow to the rescue
Let's summarize the key pain points we discovered across all three scenarios:
Serialization/Deserialization Overhead: Every time data moves between libraries or processes, we need expensive conversions that waste CPU cycles and create processing delays.
Memory Inefficiency: Each library or process must maintain its own copy of the data, leading to high memory usage and potential system bottlenecks.
Data Type Inconsistencies: Different libraries and languages interpret data types differently, causing potential data corruption or loss.
Complex Integration: Setting up data sharing between different technologies requires significant engineering effort and expertise.
Enter Apache Arrow. Arrow is a framework that directly addresses these challenges by providing:
A standardized in-memory format that eliminates the need for constant data conversions
Zero-copy reads that allow multiple libraries and processes to share data without duplicating memory
A rich type system that maintains data consistency across different programming languages
Simple, unified APIs that make data sharing straightforward across various technologies
Apache Arrow originated in 2016 as a collaborative effort between the Apache Calcite, Cassandra, Drill, Hadoop, HBase, Impala, Kudu, Phoenix, Spark, and Storm projects. The goal was to create a standardized columnar memory format for flat and hierarchical data.
The project emerged from the realization that many big data systems were independently creating similar in-memory formats and spending significant engineering resources on data serialization. By standardizing this format, Arrow aimed to eliminate this redundant work and enable seamless data exchange.
Arrow in Action: Solutions to Common Data Sharing Scenarios
Now that you understand the basics of Apache Arrow, let's explore how it addresses each scenario we discussed.
Scenario 1 with Arrow: Libraries Share Data Without Copies
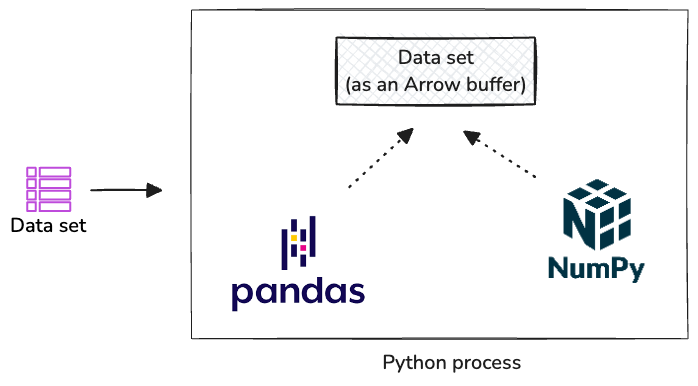
When using Arrow, Pandas, and NumPy, you can work with the same dataset directly in memory. Here's how it works:
Single Memory Buffer: The dataset lives in a single Arrow-formatted memory buffer (Arrow internally represents this as a RecordBatch, which we will cover in a future post) that both libraries can read
Zero-Copy Access: Each library directly accesses the data without creating copies or converting formats
Consistent Types: Arrow's type system ensures both libraries interpret the data identically
This eliminates serialization overhead and memory duplication, making operations significantly faster.
Scenario 2 with Arrow: Efficient Inter-Process Communication
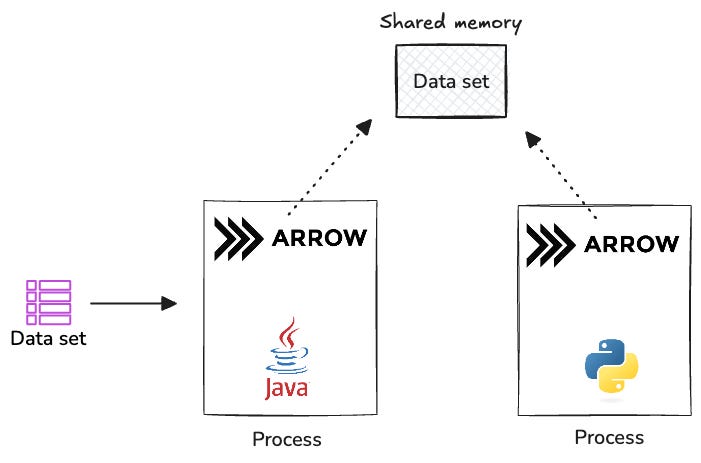
Arrow transforms how the Java producer shares data with the Python consumer on the same machine:
Shared Memory: Arrow uses memory mapping to let both processes access the same data buffer
No Serialization: The data stays in Arrow format throughout, eliminating conversion steps
Built-in IPC: Arrow provides ready-to-use IPC mechanisms, removing the need for custom implementations
This approach makes data sharing between processes nearly as fast as working with local memory.
Scenario 3 with Arrow: Optimized Network Transfer
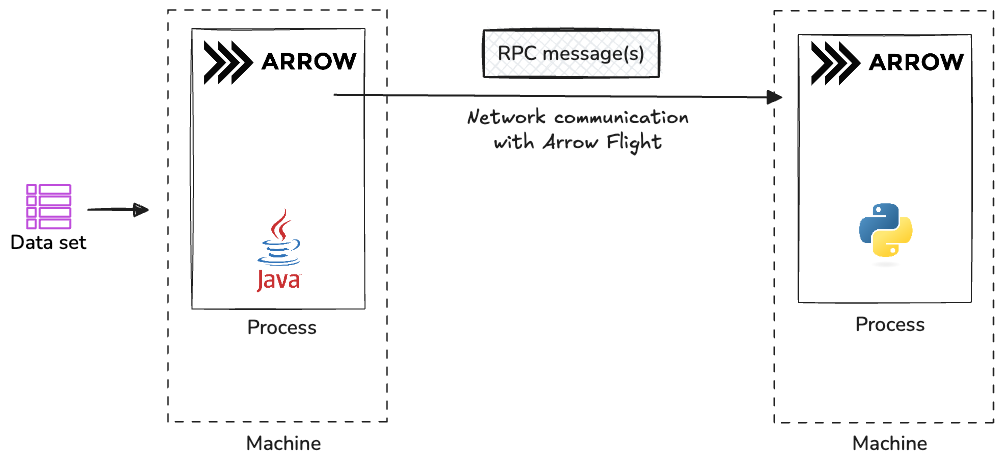
Arrow improves network communication between Java and Python processes through Arrow Flight:
Streaming Protocol: Arrow Flight enables efficient data streaming without intermediate formats
Column Selection: Consumers can request specific columns, reducing network traffic
Built-in Schema Management: Arrow handles schema coordination automatically
Compression Support: Arrow can compress data during transfer while maintaining its columnar format
These features make network transfers faster and more reliable while reducing bandwidth usage.
Key Benefits Across All Scenarios
Using Arrow brings several consistent advantages:
Predictable Performance: Direct memory access and zero-copy operations provide consistent, high performance
Reduced Complexity: Arrow's unified API removes the need for custom data conversion code
Memory Efficiency: Shared memory access eliminates redundant data copies
Type Safety: Arrow's comprehensive type system prevents data corruption across language boundaries
Current Usage and Adoption
As of 2025, Apache Arrow has become a foundational technology in the data analytics ecosystem. Here are some major systems leveraging Arrow:
Several major analytics engines have integrated Arrow into their core functionality. Spark leverages Arrow to optimize data transfer between JVM and Python processes, while DuckDB has made Arrow its primary data exchange format. Snowflake has also adopted Arrow to enhance the efficiency of its Python connector, demonstrating the framework's versatility in large-scale data processing systems.
In the data science ecosystem, popular tools have started using Arrow to improve their performance and interoperability. Pandas uses Arrow to enhance its I/O operations, while R relies on Arrow for seamless data exchange with Python and other systems. The RAPIDS suite takes this integration further by building its GPU-accelerated data science capabilities directly on Arrow's foundation. Polars, a modern DataFrame library written in Rust, has deeply integrated Arrow into its architecture, allowing efficient data exchange with other Arrow-compatible libraries without conversion overhead.
Query engines have also recognized Arrow's potential for improving data processing efficiency. Presto implements Arrow to streamline data transfer between nodes, while Apache Drill uses it to enable fast in-memory processing. Perhaps most notably, Apache DataFusion has been built entirely on Arrow, making it a prime example of how Arrow can serve as a comprehensive foundation for modern query engines.

The Arrow ecosystem has grown to include several sub-projects:
Arrow Flight: A protocol for high-performance data transfer
Arrow Flight SQL: A wire protocol for database connections
**ADBC:** Arrow Database Connectivity, a set of abstract APIs in different languages for working with databases and Arrow data.
Arrow Dataset: A format for organizing large datasets
Parquet: Close integration with the columnar storage format
This widespread adoption has made Arrow the de-facto standard for in-memory analytics, particularly in scenarios requiring high-performance data exchange between different systems and programming languages.
Wrapping Up
In this post, I've only scratched the surface of what Apache Arrow is capable of doing in the data and analytics space. Its fundamental purpose is to introduce standardization and make analytics operations more efficient and easier to work with. While we've covered the basic concepts and some common scenarios, there's still much more to explore.
Several crucial aspects of Arrow deserve deeper examination, including:
Detailed memory layouts of Arrow’s columnar data structures
Advanced IPC mechanisms
Arrow Flight's comprehensive features and implementations
Integration patterns with various data processing systems
I believe now you have some understanding of what Arrow is. I will explain how Arrow works in the future. I plan to continue this series through both sketch notes and in-depth posts like this one, diving into each of these topics in detail.
If you're interested in learning more about Apache Arrow and other data engineering concepts, feel free to connect with me on LinkedIn for future updates.