
A Primer on Kafka API
A vendor-neutral and language-agnostic beginners guide to fundamentals of Kafka API and its information hierarchy.

Kafka is a project that initially began within LinkedIn to build a robust, scalable message bus. It played a pivotal role in LinkedIn’s data infrastructure and was widely adopted due to its unique features and capabilities. Recognizing its potential, LinkedIn donated Kafka to the Apache Software Foundation in 2016, where it evolved into Apache Kafka, retaining its original functionality while gaining additional features and improvements.
As Kafka gained popularity and its codebase matured, several vendors forked it to provide their own Kafka distributions. Companies like Redpanda and Warpstream even went as far as to rewrite the entire codebase in different programming languages other than Java.
However, amidst all these changes, these companies strived to keep one crucial thing unchanged — the Kafka API. This standard interface plays a key role in ensuring compatibility and interoperability across different Kafka distributions.
Apache Kafka vs the Kafka API
It’s important to understand the distinction between Apache Kafka and the Kafka API, as they are two separate entities.
Apache Kafka is a distributed append-only commit log. It receives messages from producers and stores them in a fault-tolerant way, allowing consumers to fetch these messages in the order they were received. Due to its design, Kafka has been established as a reliable and highly scalable publish-subscribe messaging system for handling real-time data feeds.
You will work with Kafka through Kafka API. As a developer, you will utilize the Kafka API to write client applications that can read and write data to Kafka. As an operator, you will utilize the Kafka API to perform administrative operations on Kafka. Regardless of whether your Kafka distribution is open-source or commercial, you will still need to work with the same Kafka API. Therefore, understanding Kafka API is crucial.

In this post, we will cover the high-level concepts you would encounter when working with any Kafka distribution. This content is independent of specific programming languages and vendors. We will discuss topics conceptually without delving into the details of the Kafka protocol or API methods.
Brokers and clusters
Kafka is a distributed system where a Broker represents a single node within this system.
A broker can take on various form factors, from physical machines to virtual machines and containers. When multiple brokers are configured together, they form a Kafka Cluster. Having multiple brokers ensures load balancing and fault tolerance.
Each broker in the cluster runs the Kafka daemon as well as manages the storage.
How would you configure a client application to initially connect to one broker when there are several brokers in a cluster? You’ll need to use the Bootstrap Server address. This is the first broker your application interacts with to acquire cluster metadata, a topic that we’ll discuss in detail later.

Messages
In the Kafka world, message, record, and event all refer to the same concept — a unit of data transferred between your application and the broker.
A message consists of a key and a value. The value contains the actual data or the payload you want to send or receive. The key can take any value, including null. Typically, an attribute related to the value is nominated as the key. For example, if the value is an order object, the key can be the customer ID. The purpose of having a key is to route the message to specific partitions within a topic. We will learn about that when we get to the partitions.

Both the key and the value are represented as a byte array of a variable length. That allows Kafka to handle a diverse range of data types, from plain text to serialized objects.
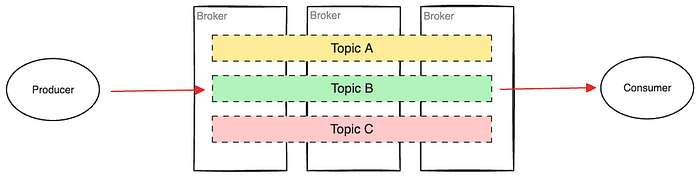
Topics
A topic is a logical grouping of messages. It’s analogous to a table from the relational database world, which keeps related records together. You can have different topics for different purposes.
Topic sits at the highest level of Kafka’s information hierarchy. As a developer, you will write client applications that produce data to and consume data from, various topics. Topic borrows the pub-sub semantics from message brokers. The topic supports concurrent data writing and reading by multiple producers and consumers. It also supports broadcast/fanout style messaging where a message produced on a topic can be consumed by multiple consumers.
Topics only permit append operations, not random mutations. Meaning, that once a message is written to a topic, you can’t go back and update it. In addition, reading from a topic is a non-destructive operation. The same consumer can come back later and re-read the message as needed. We will learn about this when we talk about consumer offsets.
Partitions and offsets
Topics are not continuous; rather, they are composed of partitions.
A topic is a logical concept, while a partition is a more tangible entity.
A topic partition is an append-only ordered log file that stores a subset of data belonging to one topic. A topic can have more than one partition and these partitions are scattered across different brokers of a cluster to provide load balancing and fault tolerance.
Why partitions?
What would happen if there’s no partition concept and Kafka keeps the topic’s data as a monolithic block? First, the topic will grow in size as more data comes and soon it will exceed the storage limits of a single machine. You can always attach more storage and make the machine taller. However, there will be a limit to that at some point.
Secondly, all consumers must consume from the broker holding that giant topic. That will increase the load on that broker because there’s no way for consumer load balancing. Moreover, backing up such a vast topic is time-consuming, and there’s a high risk of losing all its data if the broker storing it crashes.
To sum it up, having topic partitions in Kafka is beneficial because it enables the distribution of data across multiple brokers in a cluster. This distribution allows for improved load balancing and fault tolerance. It also makes the system more scalable, as the topic’s data can grow beyond the storage limits of a single machine. Additionally, partitions allow for consumer load balancing, as consumers can consume from different brokers. This makes the system more efficient and reliable, as there’s less risk of losing all data if one broker crashes.
Partition offsets
Each message in a partition gets a unique offset — a monotonically increasing integer indicating a message’s position in the partition log file. In simple terms, an offset says how far a message is located from the start of the log file.
When a message is written to a partition, it is appended to the end of the log, assigning the next sequential offset. Offsets are especially helpful for consumers to keep track of the messages they have consumed from a partition.

Message ordering and partition routing
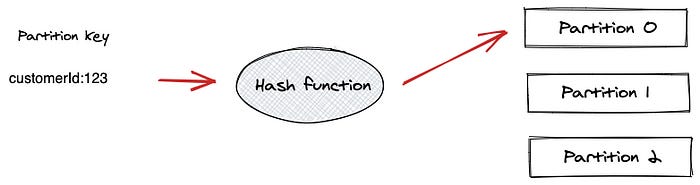
Messages written to a partition are always ordered by the time they arrive. But message ordering across a topic is not guaranteed. If you need strict ordering within a partition, you must use a partition key properly. But how?
As we learned above, you can include a key with every message. Upon receiving a message, Kafka uses a hash function on the key to determine the partition to which the message should be written. That assures that all records produced with the same key will arrive at the same partition in the exact order they were sent.
Partition replication — leaders and follows
A partition can have more than one copy. They are replicated for two main reasons: fault tolerance and high availability.
By maintaining multiple copies of the same data, Kafka ensures that if one broker fails, another broker can serve the data. This redundancy allows the system to continue functioning even in the face of failures. Additionally, by having replicas spread across multiple brokers, Kafka can balance the load of read and write requests, improving the system’s performance.
When you create a topic, you can optionally specify the partition count as well as the replication factor. If a topic has 10 partitions with a replication factor set to 3, there will be a total of 10x3=30 partitions stored across the cluster.
Partition leaders and followers
Each partition replica is either a leader or a follower. The leader replica handles all read and write requests for the partition, while the follower replicas passively replicate the leader. If the leader fails, one of the follower replicas will automatically become the new leader.

How does Kafka determine the partition leader? Kafka depends on a distributed consensus algorithm implementation, such as Apache Zookeeper, to handle leadership elections for partitions. When a broker fails and comes back online, or when a new broker is added to the cluster, ZooKeeper helps in electing the new leader for each partition. The election process ensures that at any given time, only one broker acts as the leader for a particular partition.
However, Kafka’s dependency on Zookeeper is being deprecated and replaced with KRaft. Some brokers, such as Redpanda, incorporate a native Raft implementation into the broker.
Segments
While I mentioned that partitions are tangible, that’s not exactly the case. A partition is further broken down into segments.
A Segment is the smallest unit of data containment of Kafka storage, which is essentially an append-only ordered log file that holds a subset of messages belonging to a partition. Multiple segments get together to form a partition.
For each partition, there is only one active segment that always receives data. Once enough messages accumulate in the active segment, it is closed or “rolls over” to the next active segment. This segment size is configurable.

Messages in closed segments can be deleted or compacted to save disk space. This is also configurable. Moreover, with Tiered Storage, you can archive older log segments into cost-efficient storage, like an S3 bucket to reduce the storage cost.
Unlike partitions, segments are not visible and accessible to developers. They particularly belong to the storage and operations side of things.
Kafka clients
We say Kafka is a dumb pipe while producers and consumers are smart endpoints. They are thick clients with lots of smart logic embedded in the client SDK.
As a developer, you can write a Kafka client in any programming language where a corresponding Kafka client SDK is available. Java and Scala being the default, Kafka client SDKs are available for languages, including Python, .NET, Go, Rust, C++, etc.
A Producer is a client application that generates messages and sends them to a Kafka topic. The SDK exposes the send() method for producing, which is an overloaded method allowing topic name, key, value, and partition ID as parameters. The SDK groups messages by partition, batches them together, and sends each batch to the broker when the batch size reaches a certain threshold.
A Consumer is a client application that reads messages from a Kafka topic. The Kafka client SDK provides methods to consume messages either one by one or in batches. Consumers can subscribe to one or more topics and consume messages in the order they were written.
A Consumer Group is a feature that allows a pool of consumers to divide up the work of processing records. When multiple consumers are subscribed to a topic and belong to the same consumer group, each consumer in the group will receive a subset of the records. Kafka ensures that a message is only consumed by one consumer in the group and balances the consumers in case of failure, making it a useful feature for both scalability and fault tolerance.

Wrap up
In conclusion, we’ve covered the fundamental concepts and components of Kafka and the Kafka API. We discussed how Kafka functions as a distributed append-only commit log, and how the Kafka API offers a standard interface for interacting with it.
We explored the concepts of brokers and clusters, messages, topics, partitions, offsets, and replication. We also delved into the importance of segments and the role of Kafka clients. Understanding these concepts is crucial for anyone working with Kafka, regardless of the specific distribution or programming language used.
For a hands-on learning experience, beginners can follow the Kafka Building Blocks course that Redpanda University offers.